




Watch the extended addition to learn how to make shard database reporting easily accessible and updatable with real-time results, no set-up, and without complex synchronization.
[email-download download_id=”8649″ contact_form_id=”9304″]
Why use a Shard database architecture?
First, performance. By distributing the table across multiple databases and hardware you can distribute the load. For example, if you have an app that peaks at one million inserts per second, but your database can only do 500k/s, if you distribute the writes evenly across both, you can now meet your peak demand.
Second, slight derivative of performance – query performance. We have seen databases that have grown over a terrabyte and the query performance was not adequate. By spreading the database into shards by common query parameters, the performance for the queries increased significantly.
Another reason to shard that it might be easier for the application developer to add additional groups (customers, companies, organizations, etc) by simply adding an additional database. This is usually an evolution of an application that was limited to one group, but noticed a need to be “multi-tenant.” It is sometimes easier to adjust the connection string for the each group rather than rewrite the application. Well, at least it was easier for the developer when he made the decision.
Last, data segmentation. For example, some applications create a database for each month. This can either be for performance, ease of application development, or a good backup/recovery strategy.
Shard Challenges
The most obvious problem is trying to find the correct data. When querying, you must understand the relationship between the databases before you can understand the content.
Second, in order to determine the sum of the data, you must join all the databases together. Creating complex queries to determine the needed result can be time consuming, and the resulting query is usually quite brittle, since the databases, by nature, will change regularly.
Finally, ensuring that ID columns are unique can be difficult. Most tables use an “identity” column for creating the ID so that it is unique within the table. These are usually an incrementing integer – First Row = 1, Second Row = 2, Third = 3, 4, 5 etc.. This is efficiently handled by the database and assures that no two IDs within a table are the same. Unfortunately, there is no mechanism to do this across databases without having this logic in the application. More often than not, this is not accounted for, and there are duplicate ID columns.
Common Shard Reporting Challenges
Usually the first approach is for the application to do its own reporting. Since it has the logic to create the shards, it also knows how to bring the data back together for reporting purposes. While useful, this is the least useful solution. It leaves all reporting to the mercy and schedule of the development team. At some point, you will find yourself copying data from the application to excel to answer that question you really care about. This solution never scales!
Then common approach to this problem is to move all the databases into a single data warehouse. There are a number of techniques to move the data – real-time replication, off hours sync, or backup copy. Either way, the goal is to create a copy that can be queried as if the sharding had not occurred.
Data Warehouse Drawbacks
Only the most intrepid among you should try to tackle this. First, you need to procure a huge database that can handle the sum of all the databases. We have seen shards spread across 60 machines with terabytes of data.
After procurement and schema development, you have to have a strategy for syncing the data that can be reproduced at regular intervals. For most implementations, we see this fall to weekly synchronization. Mind you, all implementations started with the goal of being real-time replication. It is, unfortunately, a difficult problem to solve consistently. Most solutions are fragile, cause unforeseen complications, and lead to unexpected delays. The consistent solutions we have found in the field take the weekly backups as inputs to the warehouse. Therefore, reports will always lag by one week.
Additionally, the warehouse needs to be aware of the “duplicate ID column” issue. In some instances, this is a non-issue. In other words, it kills the project.
Once you have copied the data, it is no longer editable. It seems obvious, but we have run into an example where half the tables had lookup values that were incorrect. Fixing it in the warehouse is easy. Getting the results fixed in the individual tables was near impossible.
Our Shard AppComm with Enterprise Enabler
Stone Bond Technologies has created a Shard AppComm for native connectivity to relational databases. Benefits include:
- Async Reads
- Unique IDs that span the entire database
- Real-Time access
- Writeback-allows the data to be immediately actionable
A robust reporting solution is created when the Shard AppComm is used in conjunction with our Data Virtualization platform. Furthermore the AppComm reduces the complexity and fragility of other solutions.
How It Works
The AppComm has a configurable list of databases which it uses to stream data to our virtualization layer. For peak performance, it streams asynchronously. This allows the AppComm to actually increase throughput over standard SQL Connections. During the transfer of data, it splices the rows together bring careful to create a unique ID per database. In addition to making the rows unique, unique IDs allow you to join multiple tables together from different databases, and the Primary/Foreign keys remain synchronized. Last, since the AppComm understands how to differentiate IDs and databases, it allows the table to be up-dateable.
Example:
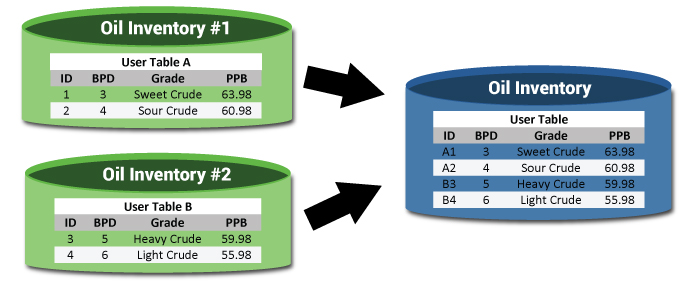
Notice that the table, while coming from different databases, looks like it is a single table. The IDs have also been updated*.
Now that the data is all in one table, we can use that to aggregate the data. For example, we could now determine how much oil we have by region, what is the average price per grade across all databases. This information was painful, if not impossible to determine, and it is now queryable in real time.
Last, we can update the data. If you find an inconsistency, you can fix all the data:
Update oil_inventory set grade = 'good' where PPB > 60
Or maybe you just have an individual row you need to fix:
Update oil_inventory set grade = 'test' where ID = a2
*note – the unique indexes in the example is a simplification. The algorithm is more complex than adding a letter to the ID.